Ticket Master
Requirements
Functional Requirements
Core Requirement
- Users should be able to view events.
- Users should be able to search for events.
- Users should be able to book tickets to events.
Below the line (out of scope)
- Users should be able to view their booked events.
- Admins or event coordinators should be able to add events.
- Popular events should have dynamic pricing.
Non-Functional Requirements
Core Requirements
- The system should prioritize availability for searching & viewing events, but should prioritize consistency for booking events (no double booking).
- The system should be scalable and able to handle high throughput in the form of popular events (10 million users, one event).
- The system should have low latency search (< 500ms)
- The system is read heavy, and thus needs to be able to support high read throughput (100:1).
Below the line (out of scope)
- The system should protect user data and adhere to GDPR.
- The system should be fault tolerant.
- The system should provide secure transactions for purchases.
- The system should be well tested and easy to deploy (CI/CD pipelines).
- The system should have regular backups.
The Set Up
Defining the Core Entities
- Event: Date, description, location, etc.
- User: User ID, etc.
- Performer: Name, bio, etc.
- Venue: Address, capacity, specific seat map, etc.
- Ticket: Associated event ID, seat details, pricing and status (available or sold).
- Booking:
- Records the details of a user's ticket purchase. Include user ID, ticket ID, booking date, etc.
- Key in managing the transaction aspect of the ticket purchasing process.
API or System Interface
- View events:
GET /events/{eventId} -> Event & Venue & Ticket[]
- Search events:
GET /events/search?keyword={keyword}&start={start_date}&end={end_date}&pageSize={page_size}&page={page_number} -> Event[]
- Book tickets:
POST /bookings/{eventId} -> bookingId
{
"ticketIds": string[],
"paymentDetails": ...
}
High-Level Design
-
Users should be able to view events
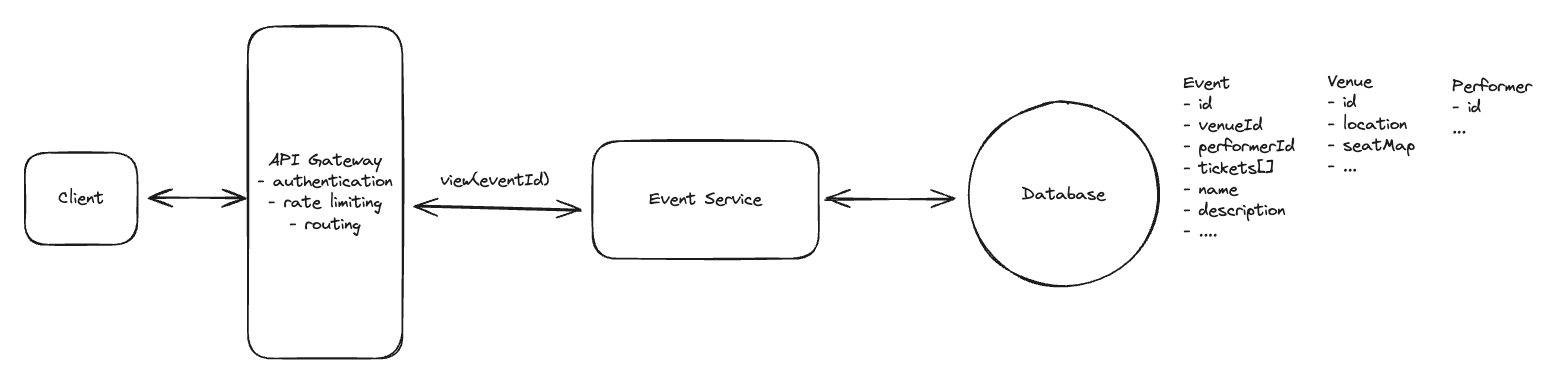
- The client makes a REST GET request with the eventId.
- The API gateway then forwards the request onto our Event Service.
- The Event Service then queries the Events DB for the event, venue, and performer information and returns it to the client.
-
Users should be able to search events
- The client makes a REST GET request with the search parameters.
- Our load balancer accepts the request and routes it to the API gateway with the fewest current connections.
- The API gateway then, after handling basic authentication and rate limiting, forward the request onto our Search Service.
- The Search Service then queries the Events DB for the events matching the search parameters and returns them to the client.
-
Users should be able to book tickets to events
-
Main thing is to avoid is two (or more) users paying for the same ticket.
-
Need to select a database supports for transactions, allow us to ensure only one user can book a ticket at a time.
-
PostgreSQL provides isolation levels and either row-level locking or Optimistic Concurrency Control (OCC) to fully prevent double booking.
- User Flow:
- The user is redirected to a booking page where they can provide their payment details and confirm the booking.
- Upon confirmation, a POST request is sent to the /bookings endpoint with the selected ticket IDs.
- The booking server initiates a transaction to:
- Check the availability of the selected tickets.
- Update the status of the selected tickets to "booked".
- Create a new booking record in the Bookings table.
- If the transaction is successful, the booking server returns a success response to the client. Otherwise, if the transaction failed because another user booked the ticket in the meantime, the server returns a failure response and we pass this information back to the client.
-
Potential Deep Dives
1. How do we improve the booking experience by reserving tickets?
- To ensure that the ticket is locked for a user while they are checking out.
- If the user abandons the checkout process, we can release the ticket.
- When the user completes the checkout process, we can mark the ticket as "SOLD".
Bad Solution: Pessimistic Locking
- Lock a specific ticket by using
SELECT FOR UPDATE. - The lock on the row is maintained until the transaction is either committed or rolled back.
- Other transactions attempting to select the same row with
SELECT FOR UPDATEwill be blocked until the lock is released.
- When it comes to unlocking, there are two cases we need to consider:
- If the user completes the checkout process, the lock is released, and the ticket is marked as "BOOKED".
- If the user takes too long or abandons the purchases, the sytem rely on the subsequent actions or session timeouts to release the lock. This introduces the risk of tickets being lock indefinitely if not appropriately handled.
- Why it is bad?
- PostgreSQL does not natively support lock timeouts with transactions.
- This solution may not scale well under high load as prolonged locks can lead to increased wait times for other users.
Good Solution: Status & Expiration Time with Cron
- Use a cron job to periodically query for rows with "RESERVED" status where the time elapsed exceeds the lock durantion and then set them to "AVAILABLE".
- Challenge:
- Delay in Unlocking
- There is an inherent delay between ticket expiration and the cron job execution, leading to inefficiencies, particularly for high-demand events.
- Ticket might remain unavailable for purchase even after the lock duration has passed, reducing book opportunities.
- Reliability Issue
- If the cron job fails or delay, it can cause siginificant disruptions in the ticket booking process, leading to customer dissatisfaction and potential loss of revenue.
Great Soltion: Distributed Locking with TTL
-
Implement a distributed lock with a TTL with Redis.
-
Redis offers high availability.
-
Steps:
- When a user selects a ticket, acquire a lock in Redis using
ticket IDwith a predefined TTL.
INCR ticket:<ticket_id>
EXPIRE ticket:<ticket_id> 30- If the user completes the purchase, the lock in Redis is manually released by the application.
DEL ticket:<ticket_id>- If the user did not complete the purchase in time, Redis automatically releases the lock after the TTL expires.
- When a user selects a ticket, acquire a lock in Redis using
2. How is the view API going to scale to support 10s of millions of concurrent requests during popular events?
- The system needs to be highly available, including during peak traffic.
Great Solution:
Caching
- Caching for data with high read rates and low update frequency to minimize the load of DB and meet HA requirement.
- A read-through cache strategy ensures data availability, with cache misses triggering a database read and subsequent cache update.
- Cache Invalidation
- Implement a TTL policy for cache entries, ensuring periodic refreshes.
Load Balancing
- Use algorithms like Round Robin or Least Connections for even traffic distribution across server instances.
Horizontal Scaling
- Add more instances of the service and load balancing between them.
3. How can you improve search to ensure we meet our low latency requirements?
Bad Solution
- Full table scan due to
LIKEwith leading wildcard, prevents from using standard indexes. ORrequires evaluating both conditions.
-- slow query
SELECT *
FROM Events
WHERE name LIKE '%Taylor%'
OR description LIKE '%Taylor%'
Good Solution: Indexing & SQL Query Optimization
Approach
- Create index columns that are frequently searched.
- Optimization:
- Using
EXPLAINto check query plan. - Avoid
SELECT *. - Use
LIMITto restrict the number of rows returned. - Use
UNIONinstead ofORfor combining multiple queries.
- Using
Challenge
- Standard indexes are less effective for queries involving partial string matches.
- Indexes increase storage requirements and slow down write operations, as each insert or update may necessitate an index update.
Great Solution: Full-text Indexes in the DB
- Utilize full-text indexes in our database.
CREATE INDEX events_fts_idx ON Events USING GIN(to_tsvector('english', name || ' ' || description));
SELECT *
FROM Events
WHERE to_tsvector('english', name || ' ' || description) @@ to_tsquery('Taylor');
Challenge
- Full text indexes require additional storage space and can be slower to query than standard indexes.
Good Solution: Full-text Search Engine like Elasticsearch
Approach
- Elasticsearch operates using inverted indexes.
- Inverted indexes allow Elasticsearch to quickly locate and retrieve data by mapping each unique word to the documents or records it appears in, significantly speeding up search queries.
- Make sure that data in Elasticsearch is always in sync with the data in our DB.
- We can use change data capture (CDC) for real-time or near-real-time data synchronization from PostgreSQL to Elasticsearch.
- Enable fuzzy search functionality with Elasticsearch, which allows for error tolerance in search queries.
- This is way we can handle typos and slight variations in spellings such as "Taylor Swift" vs "Tayler Swift".
Challenges
- Keeping the Elasticsearch index synchronized with PostgreSQL can be complex and requires a reliable mechanism to ensure data consistency.
5. How can you speed up frequently repeated search queries and reduce load on our search infrastructure?
Good Solution: Implement Caching Strategies Using Redis
Approach
- Key Design: Construct cache keys based on search query parameters to uniquely identify each query.
- Time-To-Live (TTL): Set appropriate TTLs for cached data to ensure freshness and relevance of the information.
- For example, a cache entry may look like:
{
"key": "search:keyword=Taylor Swift&start=2021-01-01&end=2021-12-31",
"value": [event1, event2, event3],
"ttl": 60 * 60 * 24 // 24 hours
}
Challenges
- Stale or outdated data in the cache can lead to incorrect search results being served to users.
Great Solution: Implement Query Result Caching and Edge Caching Techniques
Approach
- Elasticsearch has built-in caching capabilities that can be leveraged to store results of frequent queries.
- The node query cache in Elasticsearch is an LRU cache shared by all shards on a node, caching results of queries used in the filter.
- Elasticsearch's shard-level request cache is used for caching search responses consisting of aggregation. This can be used for adaptive caching strategies, where the system learns and caches results of the most frequently executed queries over time.
- Utilize CDNs to cache search results geographically closer to the user, reducing latency and improving response times. For example, AWS CloudFront.
Challenges
- Ensuring consistency between cached data and real-time data requires sophisticated synchronization mechanisms. You need to ensure you invalidate the cache whenever the underlying data changes (like when a new event is announced).